一、介绍
1.1 Stable Diffusion
Stable Diffusion是2022年发布的主要用于 文本生成图像 的深度学习模型,也就是常说的txt2img的应用场景,通过给定 文本提示词(text prompt),该模型会输出一张匹配提示词的图片。
Stable Diffusion是基于“潜在扩散模型”(latent diffusion model;LDM)的模型
- 原理图(基于LDM论文)
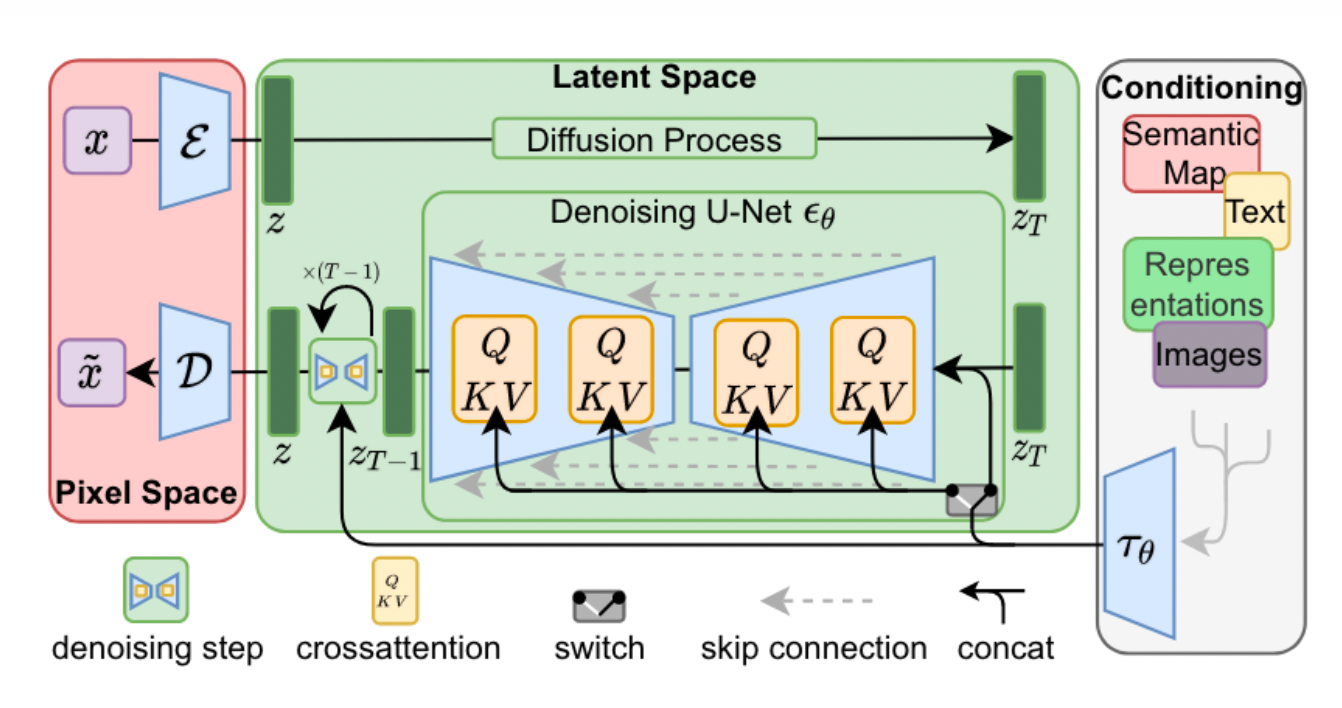
- 变分编码器 Vector Quantised Variational AutoEncoder,VQ-VAE
扩散模型 Diffusion Model, DM
条件控制器 Conditioning
应用场景
txt2img(文生图)、img2img(图生图)、Depth-to-image(深度图生图)、Inpainting(图片修复)
1.2 Stable Diffusion WebUI
基于Stable Diffusion的Web端操作页面
二、部署
1. 安装部署
1.1. 简易安装步骤
前提条件:Windows系统+Nvidia独立显卡+最低4G显存
1.2. 专业安装步骤(推荐)
- 环境准备
git、Python3.10及以上版本、最低4GB显存(低显存也能跑)
Nvidia显卡需要安装CUDA、AMD显卡需要安装Ort
- 下载&部署
步骤参考 stable-diffusion-webui 文档
- 启动
在项目根目录下执行
# 更多参数参考github文档,启动后会自动安装需要的包
./webui.sh --medvram --theme dark
解决疑难杂症
先在SDWebui github上的文档查找解决方案,没有了再参考网上相关解决方案
2. 插件
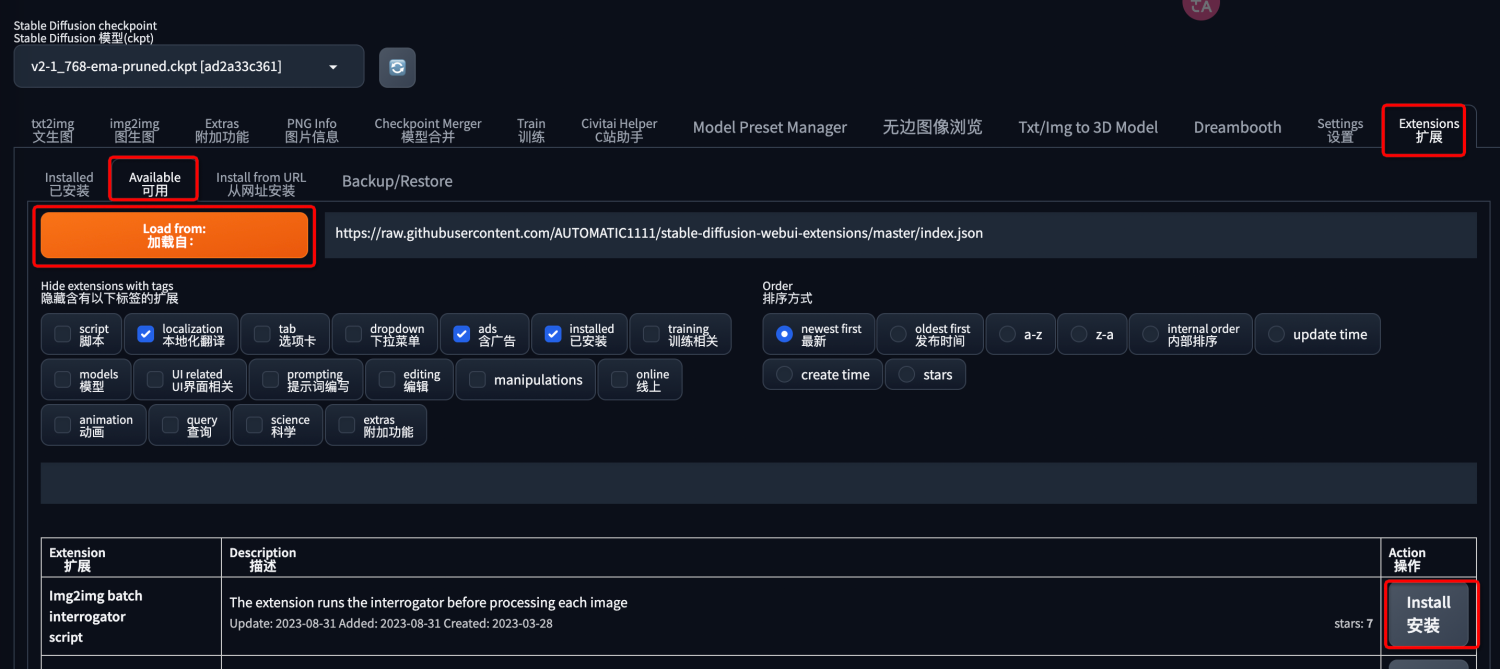
- 页面安装(需🪜)
首页 -> Extensions -> Available; 点击Load from加载插件 或者 从URL安装插件 安装完成后点击 Settings -> Reload UI
本地安装
下载插件项目后放在 /extensions 目录下部分插件推荐
| 名称 | 简介 |
|---|---|
| sd-webui-bilingual-localization | 双语翻译 |
| stable-diffusion-webui-localization-zh_CN | 汉化包,搭配上面的使用 |
| sd-webui-controlnet | 模型细节控制 |
| sd-webui-infinite-image-browsing | 图片管理器 |
- 汉化
Settings -> User interface -> Localization,选择zh_CN
完成后点击 Settings -> Reload UI
3. 所需资源文件
注意,资源文件名中不要有汉字
下载完成后需要重启下SD Webui才能记载到资源
- 下载地址
炼丹阁 (www.liandange.com) 国内,大多来自于civitai
- 资源类型介绍
| 描述 | 后缀名 | 存放位置 | 作用 | 备注 |
|---|---|---|---|---|
| 权重文件 | ckptsafetensors | /stable-diffusion-webui/models/Stable-diffusion | 基础模型文件,必须 | 部分模型会附带(.vae.pt)或配置文件(.yaml)如果一个模型附带配置文件或者VAE,需要先把它们的文件名改为相同的文件名,然后再放入目录中 |
| Lora | /stable-diffusion-webui/models/Stable-diffusion | 非必须,生成的图片的风格更加细腻 | ||
| ControlNet | 非必须,模型细节控制简单点理解就是,按我给的图片风格生成新的图片 | 需要插件支持 | ||
| vae | 解码器/滤镜,非必须 |
三、简单使用
1. 常用功能
text2img-文生图
img2img-图生图、绘图、局部重绘
PNG Info-图片信息,可将图片信息发送到text2img和img2img中
2. 参数介绍
| 参数 | 说明 |
|---|---|
| Prompt | 正向提示词 |
| Negative prompt | 反向/消极的提示词 |
| Width、Height | 图片尺寸。尺寸越大越耗性能,生成时间越久。 |
| Batch count | 生成批次 |
| Batch size | 每一批生成的图片数 |
| CFG scale | AI 对描述参数(Prompt)的倾向程度。值越小生成的图片越偏离你的描述,但越符合逻辑;值越大则生成的图片越符合你的描述,但可能不符合逻辑。 |
| Sampling method | 采样方法。有很多种,但只是采样算法上有差别,没有好坏之分,选用适合的即可。 |
| Sampling steps | 采样步长。太小的话采样的随机性会很高,太大的话采样的效率会很低,拒绝概率高(可以理解为没有采样到,采样的结果被舍弃了)。 |
| Seed | 随机数种子。生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。不懂的话,用随机的即可。 |
3. 描述词学习
通过点点点生成描述词
知识点: 权重通过 {描述词} 形式表示,高权重词写法{{{描述词}}}
4. 效果展示
自行下载对应模型
prompt: a girl
Negative prompt: ugly
Steps: 40, Sampler: Euler a, CFG scale: 7, Seed: 1348569158, Size: 512x512, Model hash: e7aab5067d, Model: caricature, Clip skip: 7, ENSD: 31337, Eta: 0.68, Version: v1.6.0

prompt: a girl,Delicate face, HD, extreme detail, master of realism, short-sleeved jeans
Negative prompt: Ugly faces, extra fingers, extra hands, discordant images
Steps: 35, Sampler: Euler a, CFG scale: 7, Seed: 123124, Size: 512x512, Model hash: e4a30e4607, Model: realHuman_majicmixRealistic_v6, Clip skip: 7, ENSD: 31337, Eta: 0.68, Version: v1.5.1-RC-3-geb6d330b

5. 扩展




