一、专业术语
1. 角色名称
- Product
消息生产者
- Consumer
消息消费者
- Push Consumer
消息消费-推模式,应用通常向 Consumer 对象注册一个Listener接口,一旦收到消息,Consumer对象立刻回调Listener接口方法。
- Pull Consumer
消息消费-拉模式,应用通常主动调用 Consumer 的拉消息方法从 Broker 拉消息,主动权由应用控制。
- ProducerGroup
一类 Producer 的集合名称,这类 Producer 通常发送一类消息,且发送逻辑一致。
- ConsumerGroup
一类 Consumer 的集合名称,这类 Consumer 通常消费一类消息,且消费逻辑一致。
- Broker
消息中转角色,负责存储消息,转发消息,一般也称为 Server。在 JMS 规范中称为 Provider。
- Message Queue
消息存储队列,长度无线(offset作为数据下标,long类型64位,理论上在 100 年内不会溢出,所以认为是长度无限)
2. 消费模式
- 广播消费
一条消息被多个 Consumer 消费,每个Consumer都会至少消费一次消息,广播消费中的 Consumer Group 概念可以认为在消息划分方面无意义。
在 CORBA Notification 规范中,消费方式都属于广播消费。在 JMS 规范中,相当于JMS publish/subscribe model
- 集群消费
一个 Consumer Group 中的 Consumer 实例平均分摊消费消息。
- 顺序消费
消费消息的顺序要同发送消息的顺序一致(局部顺序),一类消息为满足顺序性,必须Producer单线程顺序发送到同一个队列,
这样 Consumer 就可以按照 Producer 发送 的顺序去消费消息。
- 普通顺序消息
顺序消息的一种,正常情况下可以保证完全的顺序消息,但是一旦发生通信异常,Broker 重启,由于队列 总数发生发化,哈希取模后定位的队列会发化,产生短暂的消息顺序不一致。
- 严格顺序消息
顺序消息的一种,无论正常异常情况都能保证顺序,但是牺牲了分布式 Failover(故障转移) 特性,即 Broker 集群中只 要有一台机器不可用,则整个集群都不可用,服务可用性大大降低。 如果服务器部署为同步双写模式,此缺陷可通过备机自动切换为主避免,不过仍然会存在几分钟的服务不可用。
目前已知的应用只有数据库 binlog 同步强依赖严格顺序消息,其他应用绝大部分都可以容忍短暂乱序,推
荐使用普通的顺序消息。
二、部署
- 队列模型的消息中间件,高性能、高可用、高实时、分布式特点
- Producer、Consumer、队列都可以分布式
- 能够保证严格的消息顺序
- 提供消息推拉消息模式
- 亿级消息堆积能力
- 较少依赖
1.物理部署结构
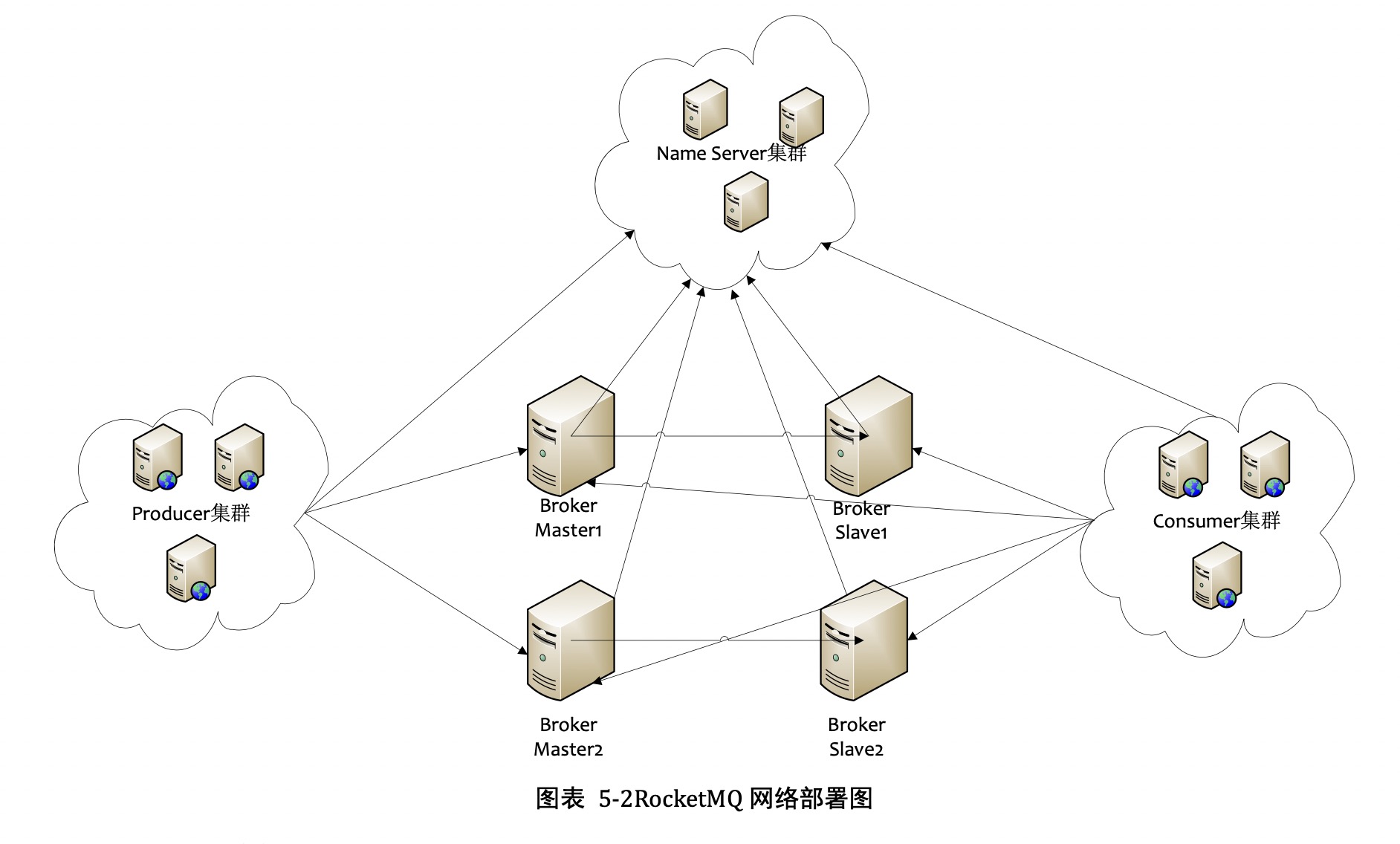
1.NameServer
无状态节点,可集群部署,节点之间无通信
2.Broker
分为Master和Slave,一个master可以对应多个slave,但是一个slave只能对应一个master; master和slave的对应关系通过指定相同的BrokerName不同的BrokerId来定义,BorkerId为0标识master,非0标识slave。master可以部署多个。
每个Broker和NameServer集群中的所有节点建立长连接,定时注册Topic信息到所有的NameServer中
3.Producer
Producer与NameServer集群中其中一个节点(随机选择)建立长连接,定期拉取Topic路由信息,并向提供Topic服务的Master建立长连接,并定时发送心跳。Producer完全无状态,可集群部署
4.Consumer
Consumer与NameServer集群中的其中一个节点建立长连接,定期获取Topic路由,并向提供Topic服务的Master、Slave建立长连接,并定时发送心跳。Consumer订阅规则由Broker配置决定,既可以从Master订阅消息,也可以从Salve消息
2.逻辑部署结构

三、存储特点
1.零拷贝原理
Consumer消费消息过程中使用了零拷贝
- 零拷贝相关链接
- 零拷贝方式
1.mmap+write方式(mmap将一个文件或者其它对象映射进内存)
优点:使用小块文件传输,效率高,支持频繁调用
缺点:不能很好的利用DMA方式(Direct Memory Access,直接存储器访问),会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash文件
2.使用sendfile方式
优点:可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全问题
缺点:小块文件效率低于mmap方式,只能BIO方式传递,不能使用NIO。
RocketMQ选择了mmap+write方式,因为现有小块数据传输需求,效果比sendfile更好
2.文件系统
RocketMQ 选择 Linux Ext4 文件系统
原因:
Ext4 文件系统删除 1G 大小的文件通常耗时小于50ms,而 Ext3 文件系统耗时约 1s 左右,且删除文件时,磁盘 IO 压力极大,会导致IO写入超时。
文件系统层面需要做以下调优措施
文件系统 IO 调度算法需要调整为 deadline,因为 deadline 算法在随机读情冴下,可以合并读请求为顺序跳跃方式,从而提高读 IO 吞吐量。
3.数据存储结构&存储目录结构


四、关键特性
1.单机支持1万以上持久化队列
| 8Byte | 4Byte | 8Byte |
| CommitLogOffset | Size | Message Tag Hashcode|
1.所有数据单独存储到CommitLog文件中,完全顺序写,随机读
2.对最终用户展现的队列实际只存储消息在CommitLog的位置信息,使用串行方式刷盘
2.刷盘策略
先写入系统pageCache 然后刷盘,保证内存与磁盘都有一份数据,访问时从内存中读取
- 同步刷盘
1. 写入 PAGECACHE 后,线程等待,通知刷盘线程刷盘。
2. 刷盘线程刷盘后,唤醒前端等待线程,可能是一批线程。
3. 前端等待线程吐用户迒回成功。
- 异步刷盘
同步刷盘与异步刷盘的唯一区别是异步刷盘写完 PAGECACHE 直接返回,而同步刷盘需要等待刷盘完成才返回
3.消息查询
- 按照MessageId查询消息
| 8Byte | 8Byte |
|消息所属Broker地址|CommitLogOffset|
- 按照MessageKey查询消息
|4Byte|8Byte|4Byte|4Byte|
|keyHash|CommitLogOffset|Timestamp|NextIndexOffset|
五、消息过滤
1.简单消息过滤
通过topic和 tags进行过滤
consumer.subscribe("TopicTest1","TagA || TagB");
2.高级过滤方式
RocketMQ 提供了基于表达式与基于类模式两种过滤模式
可以实现 MessageFilter 接口,实现自定义过滤

